
We discovered today that some implicit assumptions we had about AKS at smaller scales were incorrect.
Suddenly new workloads and jobs in our Radix CI/CD could not start due to insufficient resources (CPU & memory).
Even though it only caused problems in development environments with smaller node sizes it still surprised some of our developers, since we expected the size of development clusters to have enough resources.
I thought it would be a good chance to go a bit deeper and verify some of our assumptions and also learn more about various components that usually “just works” and isn’t really given much thought.
First I do a kubectl describe node <node> on 2-3 of the nodes to get an idea of how things are looking:
| |
So we are obviously hitting the roof when it comes to resources. But why?
Node overhead
We use Standard DS1 v2 instances as AKS nodes and they have 1 CPU core and 3.5 GiB memory.
The output of kubectl describe node also gives us info on the Capacity (total node size) and Allocatable (resources available to run Pods).
| |
So we have lost 60 millicores / 6% of CPU and 1685MiB / 48% of memory. The next question is if this increases linearly with node size (the percentage of resources lost is the same regardless of node size) or is fixed (always reserves 60 millicores and 1685Mi of memory), or a combination.
I connect to another cluster that has double the node size (Standard DS2 v2) and compare:
| |
So for this the loss is 69 millicores / 3.5% of CPU and 2445MiB / 35% of memory.
So CPU reservations are close to fixed regardless of node size while memory reservations are influenced by node size but luckily not linearly.
What causes this “waste”? Reading up on kubernetes.io gives a few clues. Kubelet will reserve CPU and memory resources for itself and other Kubernetes processes. It will also reserve a portion of memory to act as a buffer whenever a Pod is going beyond it’s memory limits to avoid risking System OOM, potentially making the whole node unstable.
To figure out what these are configured to we log in to an actual AKS node’s console and run ps ax|grep kube and the output looks like this:
| |
To log in to the console of a node, go to the MC_resourcegroup_clustername_region resource-group and select the VM. Then go to
Boot diagnosticsand enable it. Go toReset passwordto create yourself a user and thenSerial consoleto log in and execute commands.
We can see --kube-reserved=cpu=60m,memory=896Mi and --eviction-hard=memory.available<750Mi which adds up to 1646Mi which is pretty close to the 1685Mi that was the gap between Capacity and Allocatable.
We also do this on a Standard DS2 v2 node and get --kube-reserved=cpu=69m,memory=1638Mi and --eviction-hard=memory.available<750Mi.
So we can see that the memory of kube-reserved grows almost linearly and seems to always be about 20-25% while CPU reservations are almost the same. The memory eviction buffer is always fixed at 750Mi which would mean bigger resource waste as nodes decrease in size.
CPU
| Standard DS1 v2 | Standard DS2 v2 | |
|---|---|---|
| VM capacity | 1.000m | 2.000m |
| kube-reserved | -60m | -69m |
| Allocatable | 940m | 1.931m |
| Allocatable % | 94% | 96.5% |
Memory
| Standard DS1 v2 | Standard DS2 v2 | |
|---|---|---|
| VM capacity | 3.500Mi | 7.113Mi |
| kube-reserved | -896Mi | -1.638Mi |
| Eviction buf | -750Mi | -750Mi |
| Allocatable | 1.814Mi | 4.667Mi |
| Allocatable % | 52% | 65% |
Node pods (DaemonSets)
We have some Pods that run on every node, and they are installed by default by AKS. We get the resource limits of these by describing either the pods or the daemonsets.
CPU
| Standard DS1 v2 | Standard DS2 v2 | |
|---|---|---|
| Allocatable | 940m | 1.931m |
| kube-system/calico-node | -250m | -250m |
| kube-system/kube-proxy | -100m | -100m |
| kube-system/kube-svc-redirect | -5m | -5m |
| Available | 585m | 1.576m |
| Available % | 58% | 81% |
Memory
| Standard DS1 v2 | Standard DS2 v2 | |
|---|---|---|
| Allocatable | 1.814Mi | 4.667Mi |
| kube-system/kube-svc-redirect | -32Mi | -32Mi |
| Available | 1.782Mi | 4.635Mi |
| Available % | 50% | 61% |
So for Standard DS1 v2 nodes we have about 0.5 CPU and 1.7GiB memory per node for pods. And for Standard DS2 v2 nodes it’s about 1.5 CPU and 4.6GiB memory.
kube-system pods
Now lets add some standard Kubernetes pods we need to run. As far as I know these are pretty much fixed for a cluster and not related to node size or count.
| Deployment | CPU | Memory |
|---|---|---|
| kube-system/kubernetes-dashboard | 100m | 50Mi |
| kube-system/tunnelfront | 10m | 64Mi |
| kube-system/coredns (x2) | 200m | 140Mi |
| kube-system/coredns-autoscaler | 20m | 10Mi |
| kube-system/heapster | 130m | 230Mi |
| Sum | 460m | 494Mi |
Third party pods
| Deployment | CPU | Memory |
|---|---|---|
| grafana | 200m | 500Mi |
| prometheus-operator | 500m | 1.000Mi |
| prometheus-alertmanager | 100m | 225Mi |
| flux | 50m | 64Mi |
| flux-helm-operator | 50m | 64Mi |
| Sum | 900m | 1.853Mi |
Radix platform pods
| Deployment | CPU | Memory |
|---|---|---|
| radix-api-prod/server (x2) | 200m | 400Mi |
| radix-api-qa/server (x2) | 100m | 200Mi |
| radix-canary-golang-dev/www | 40m | 500Mi |
| radix-canary-golang-prod/www | 40m | 500Mi |
| radix-platform-prod/public-site | 5m | 10Mi |
| radix-web-console-prod/web | 10m | 42Mi |
| radix-web-console-qa/web | 5m | 21Mi |
| radix-github-webhook-prod/webhook | 10m | 30Mi |
| radix-github-webhook-prod/webhook | 5m | 15Mi |
| Sum | 415m | 1.718Mi |
If we add up the resource usage of these groups of workloads and see the total available resources on our 4 node Standard DS1 v2 clusters we are left with 0.56 CPU cores (14%) and 3GB of memory (22%):
| Workload | CPU | Memory |
|---|---|---|
| kube-system | 460m | 494Mi |
| third-party | 900m | 1.853Mi |
| radix-platform | 415m | 1.718Mi |
| Sum | 1.760m | 4.020Mi |
| Available on 4x DS1 | 2.340m | 7.128Mi |
| Available for workloads | 565m | 3.063Mi |
Though surprising that we lost this much resources before being able to deploy our actual customer applications, it should still be a bit of headroom.
Going further I checked the resource requests on 8 customer pods deployed in 4 environments (namespaces). Even though none of them had a resource configuration in their radixconfig.yaml files they still had resource requests and limits. Not surprising since we use LimitRange to set default resource requests and limits. The surprise was that half of them had 50Mi of memory and the other half 500Mi, seemingly at random.
It turns out that we did an update to the LimitRange values a few days ago but that only applies to new Pods, so depending on if the Pods got re-created for any reason they may or may not have the old request of 500Mi, which in our case of small clusters will quickly drain the available resources.
Read more about LimitRange here: kubernetes.io , and here is the commit that eventually trickled down to reduce memory usage: github.com
Pod scheduling
Depending on the weight between CPU and memory requests and how often things get destroyed and re-created you may find yourself in a situation where you have enough resources in your cluster but new workloads are still Pending. This can happen when one resource type (e.g. CPU) is filled before another (e.g. memory), leading one or more resources to be stranded and unlikely to be utilized.
Imagine for example a cluster that is already utilized like this:
| CPU | Memory | |
|---|---|---|
| node0 | 94% | 86% |
| node1 | 80% | 89% |
| node2 | 98% | 60% |
Scheduling a workload that requests 15% CPU and 20% memory cannot be scheduled since there are no nodes fulfilling both requirements. In theory there is probably a CPU intensive Pod on node2 that could be moved to node1 but Kubernetes does not do re-scheduling to optimize utilization. It can do re-scheduling based on Pod priority (medium.com) and there is an incubator project (akomljen.com) that can try to drain nodes with low utilization.
So for the foreseable future keeping in mind that resources can get stranded and that looking at the sum of cluster resources and sum of cluster resource demand might be misleading.
calico-node
The biggest source of waste on our small clusters is calico-node which is installed on every node and requests 25% of a CPU core while only using 2.5-3% CPU:
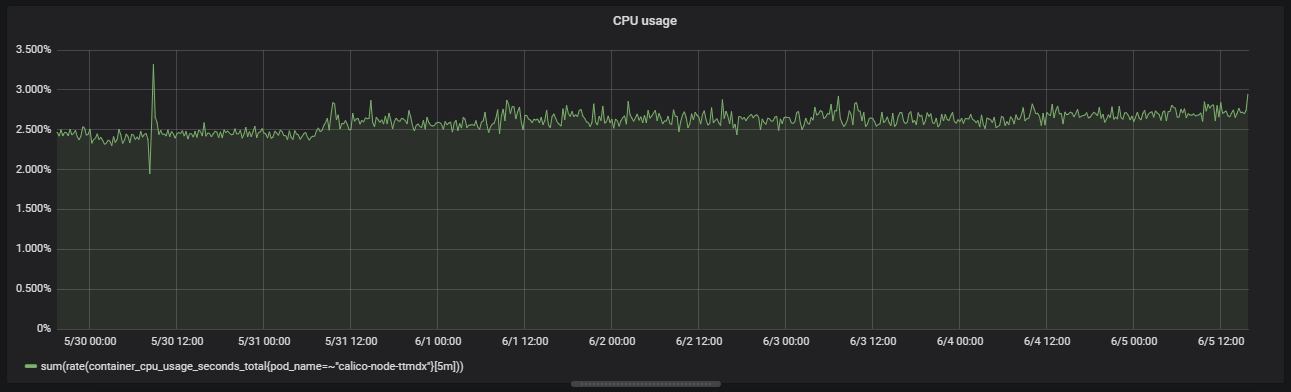
The request is originally set here github.com but I have not got into why that number was choosen. Next steps would be to do some benchmarking of calico-node to smoke out it’s performance characteristics to see if it would be safe to lower the resource requests, but that is out of scope for now.
Conclusion
- By increasing node size from
Standard DS1 v2toStandard DS2 v2we also increase the available CPU from 58% per node to 81% per node. Available memory increases from 50% to 61% per node. - With a total platform requirement of 3-4GB of memory and 4.6GB available on
Standard DS2 v2we might have more resources for actual workloads on a 1-nodeStandard DS2 v2cluster than a 3-nodeStandard DS1 v2cluster! - Beware of stranded resources limiting the utilization you can achieve across a cluster.